
Regression analysis is a cornerstone of academic research, enabling scholars to investigate relationships between variables, test hypotheses, and build predictive models. This guide will walk you through the basics of regression analysis, explain specific terms in detail, and demonstrate how Powerdrill AI can simplify your workflow. Whether you’re analyzing survey data, conducting experiments, or working with large datasets, this guide will help you unlock meaningful insights with ease.
What Is Regression Analysis?
Regression analysis is a powerful statistical tool that helps us understand the relationship between variables. At its core, it aims to model and analyze how a dependent variable (also known as the response variable) changes in relation to one or more independent variables (also called predictor variables).
Multiple regression analysis is used to understand the relationship between one dependent variable and two or more independent variables. It extends the concept of simple linear regression, which involves only one independent variable, by allowing for the inclusion of multiple factors that might influence the outcome.
Regression analysis is widely used in academic fields such as:
Social Sciences: Exploring how socioeconomic status affects educational attainment.
Health Sciences: Investigating the impact of exercise on blood pressure.
Economics: Analyzing the relationship between inflation and unemployment rates.
Environmental Studies: Examining how temperature changes affect crop yields.
For example, consider a researcher who wants to understand and predict the annual household income of people. Here, the annual household income is the dependent variable. The independent variables could be various factors from our given dataset such as the age of the primary household member, which might influence income as more experienced individuals may earn higher salaries. The education level of the primary household member is another important factor; typically, those with higher education levels like a Doctorate may have higher - paying jobs compared to those with just a High School education.
Key Terms Explained
Dependent Variable (Y): The outcome or phenomenon you aim to explain or predict.
Independent Variable(s) (X): The factors that might influence the dependent variable.
R-squared: A measure of how well the independent variables explain the variability in the dependent variable (ranges from 0 to 1, with higher values indicating better fit).
P-value: A statistical measure that helps determine the significance of an independent variable. A p-value below 0.05 is typically considered significant in academic research.
Coefficients: Numbers that represent the strength and direction of the relationship between each independent variable and the dependent variable.
How to handle categorical variables/non continuous variables?
In the given dataset for annual household income analysis, there are several categorical variables such as "Education Level", "Occupation", "Location", "Marital Status", "Employment Status", "Homeownership Status", "Type of Housing", "Gender", and "Primary Mode of Transportation". Here are the common ways to handle these categorical variables for regression analysis in Excel and with Powerdrill AI:
In Excel: Tradtional method
One - Hot Encoding
For "Education Level": First, count the number of unique categories. In this case, there are 4 categories: "High School", "Bachelor's", "Master's", and "Doctorate". Then, create 4 new columns. For each row, if the "Education Level" is "High School", the "High School" column will have a value of 1, and the other three columns will have 0s. For example, if in cell A2 the "Education Level" is "Bachelor's", then in the new "Bachelor's" column corresponding to row 2, the value will be 1, and the "High School", "Master's", and "Doctorate" columns for that row will be 0s.
This process is repeated for all categorical variables. For "Occupation", since there are multiple types like "Healthcare", "Education", "Technology", "Finance", and "Others", we create a new column for each type. If a household's "Occupation" is "Technology", the "Technology" column for that row will be 1, and the rest of the occupation - related columns will be 0s.
One - hot encoding transforms a categorical variable into a set of binary variables, allowing the regression model to understand and process the categorical information as numerical values. Each category is represented by a unique binary vector.
Creating Dummy Variables
For "Location": Suppose we have three categories: "Urban", "Suburban", and "Rural". Instead of creating 3 columns as in one - hot encoding, we create 2 columns. We can choose "Rural" as the reference category. For the "Urban" column, if the "Location" is "Urban", the value is 1, and if it is "Suburban" or "Rural", the value is 0. For the "Suburban" column, if the "Location" is "Suburban", the value is 1, and if it is "Urban" or "Rural", the value is 0.
This approach reduces the number of variables, which can be beneficial when dealing with a large number of categorical variables. For example, if "Occupation" has many categories, creating dummy variables can prevent issues like multicollinearity that may arise from having too many highly - correlated variables (as in one - hot encoding).
By choosing a reference category, we can represent the other categories relative to it. The regression model can then estimate the effect of each non - reference category compared to the reference category.
With Powerdrill AI: Automatic Handling
Powerdrill AI has built - in algorithms that can automatically recognize categorical variables in the dataset. For example, when we upload the dataset with variables like "Marital Status" and "Employment Status", it doesn't require manual encoding like in Excel.
The AI platform is designed to handle categorical variables in a more efficient way. It may use advanced techniques such as ordinal encoding for variables where there is an inherent order (although in our dataset, most categorical variables may not have a clear order). For variables without an order, it can use techniques similar to one - hot encoding or more advanced machine - learning - specific encodings under the hood.
This saves a significant amount of time and effort. Users don't need to worry about the technical details of encoding categorical variables.
After handling the categorical variables in either Excel or with Powerdrill AI, we can then use them in the regression analysis. In Excel, we include the newly created columns (from one - hot encoding or dummy variables) in the "Input X Range" for the regression analysis. With Powerdrill AI, we just tell Powerdrill to process categorical variables, then the platform will upgrade the dataset uploaded and perform the analysis using the appropriate handling of these variables.
How to do Multiple Regression Analysis in Excel?
Excel is a widely available and user - friendly tool for basic regression analysis. Let's use our synthetic dataset which focuses on various demographic and socioeconomic factors influencing annual household income. The dataset includes features such as "Age", "Education Level", "Occupation", "Number of Dependents", etc., with "Annual Household Income" being the dependent variable.
STEP 1: Data Preparation
First, ensure your data is clean. Check for any missing values. For instance, if there are missing values in the "Age" column, you can either fill them in. One way is to use the mean age of all the non - missing values. Calculate the mean by adding up all the non - missing ages and dividing by the number of non - missing entries. If there are missing values in a categorical variable like "Occupation", you might consider using the mode (the most frequently occurring occupation) to fill in. Or, if the number of missing values is small, you can choose to remove the rows with missing data.
Format your data correctly. Make sure numerical values like "Age" and "Number of Dependents" are in the correct numeric format. For categorical variables, ensure they are entered consistently, for example, all "Education Level" entries are spelled correctly as "High School", "Bachelor's", "Master's", or "Doctorate".
STEP 2: Using the Data Analysis Toolpak
If you don't have the Data Analysis Toolpak enabled, you need to do so. Go to “File” > “Options” > “Add - ins”. Select “Analysis ToolPak” and click “Go”. Check the box next to “Analysis ToolPak” and click “OK”.
Once enabled, go to the “Data” tab and click on “Data Analysis”. In the Data Analysis dialog box, select “Regression”.
STEP 3: Adjusting the Parameters
In the Regression dialog:
Input Y Range: Put the range of "Annual Household Income" data in the "Input Y Range" box. For example, if the data is from N2 to N10001, enter "$N2:N$10001".
Input X Range: Enter the ranges of independent variables like "Age", "Education Level", "Number of Dependents" in the "Input X Range" box. Excel may create dummy variables for categorical data like "Education Level".
Check the "label": If there are column headers, check the box to include the label row. This helps Excel recognize the variable names in the regression output.
The Confidence level: Set the confidence level as needed, the default is 95%.
The output range: Choose an output range for the regression results, it can be a new worksheet or an empty area in the existing one.
Check the "Residuals" option: Residuals show the difference between observed and predicted values. Large residuals mean the model may not predict accurately at those points. They're important for evaluating model quality.
Check "Standardized Residuals": They help detect outliers more effectively. Values with absolute standardized residuals over a certain threshold (e.g., 3) are likely outliers.
Check "Residual Plots": They show the relationship between independent variables and residuals. A pattern in the plot suggests the model may be misspecified. This option is useful for diagnosing potential problems.
Check "Line Fit Plots"": They compare actual and predicted values visually. If data points are widely scattered around the predicted line, the model may not fit well. This option helps assess the model's overall fit.
STEP4: Analyzing the Results
After clicking “OK”, Excel will generate a comprehensive set of results. These include the coefficients () for each variable. For example, the coefficient for "Age" will tell you how much the "Annual Household Income" is expected to change for a one - year increase in age, assuming all other variables are held constant. The standard errors, t - statistics, p - values, and the value are also provided. The value tells you how well the independent variables explain the variation in the "Annual Household Income". A value closer to 1 indicates a better fit.
How to Run Multiple Regression Analysis with AI?
Powerdrill AI is an excellent platform for simplifying and enhancing the regression analysis process. We'll continue with our synthetic dataset on annual household income.
STEP 1: Uploading the Data
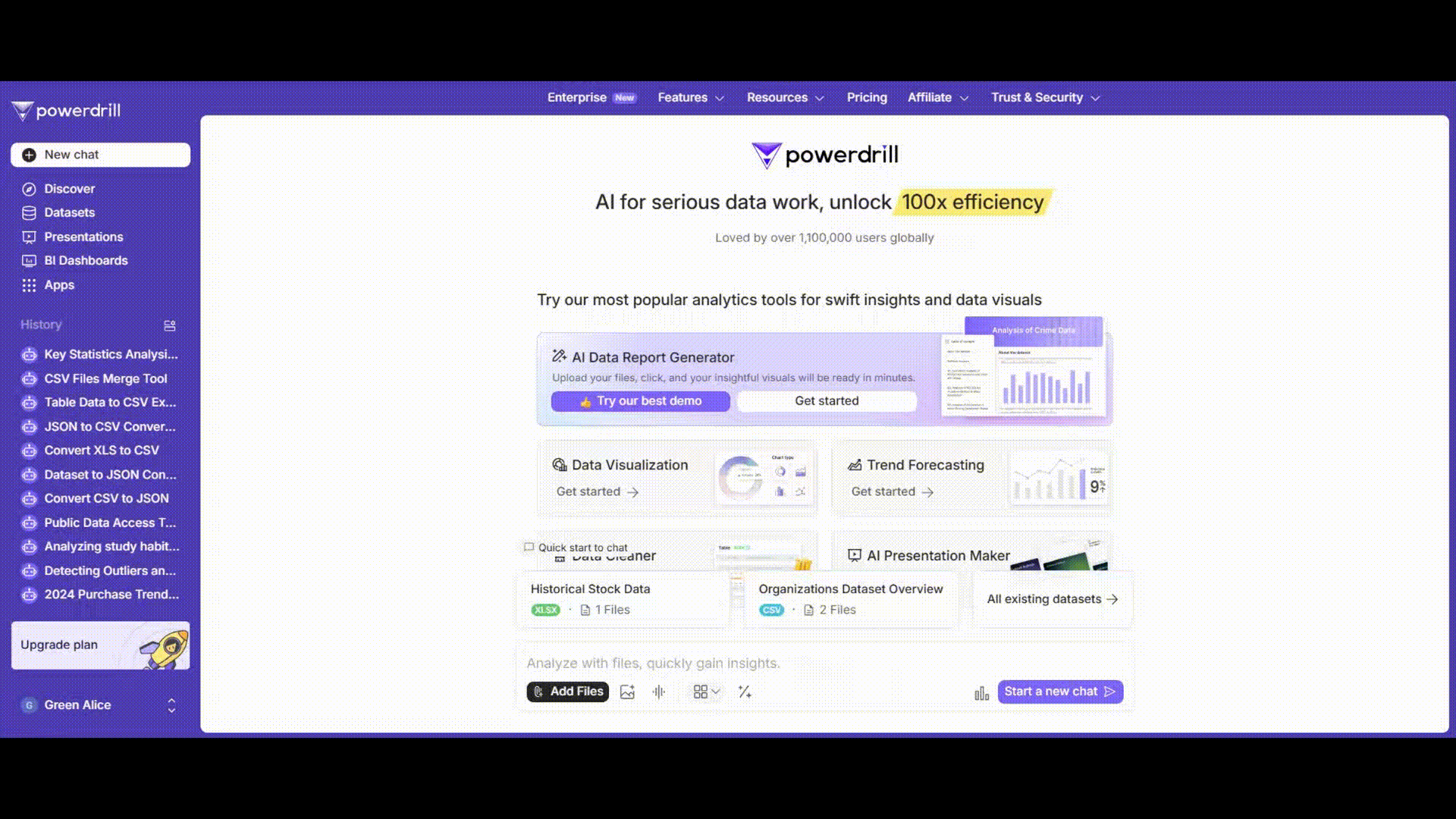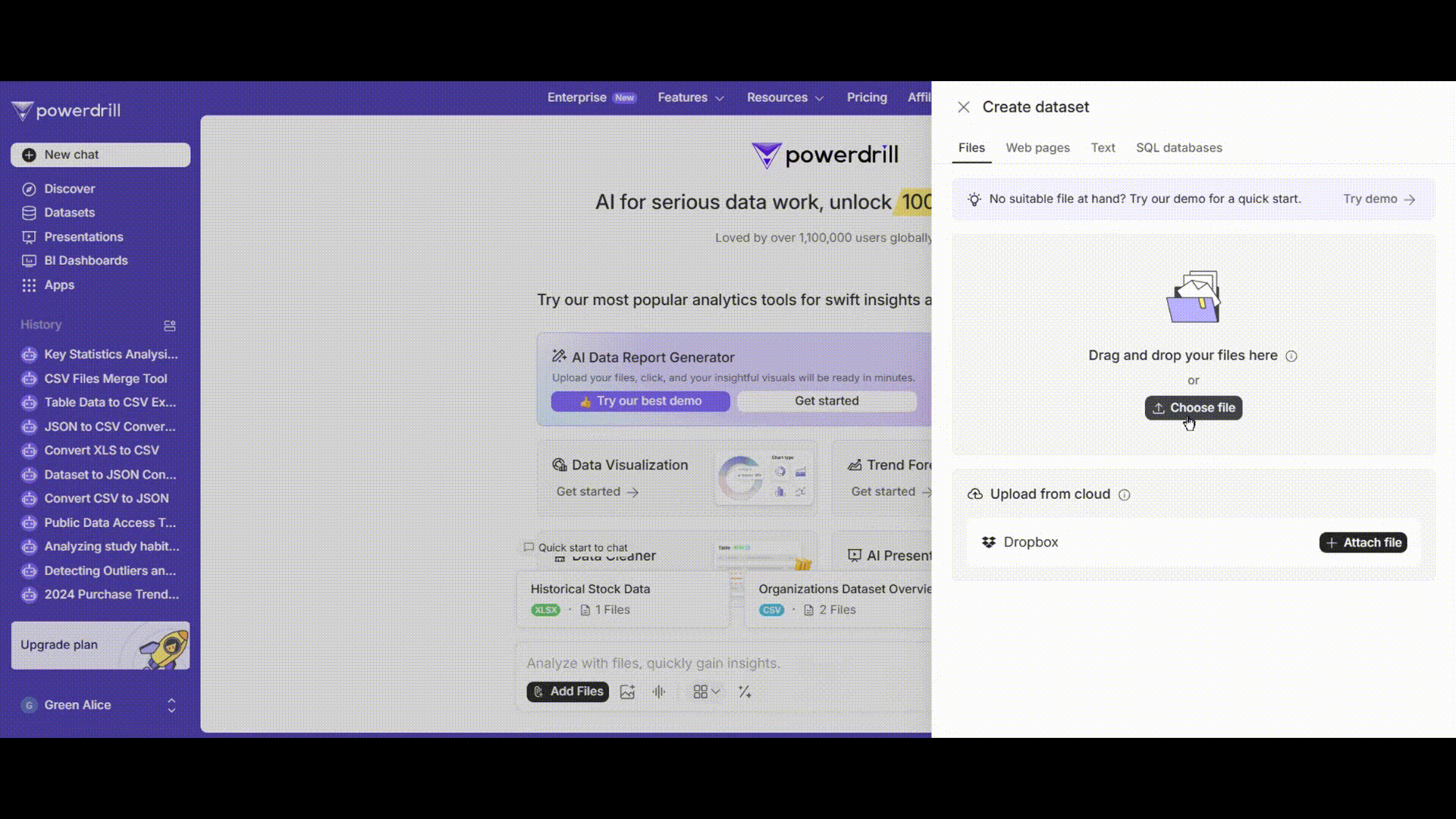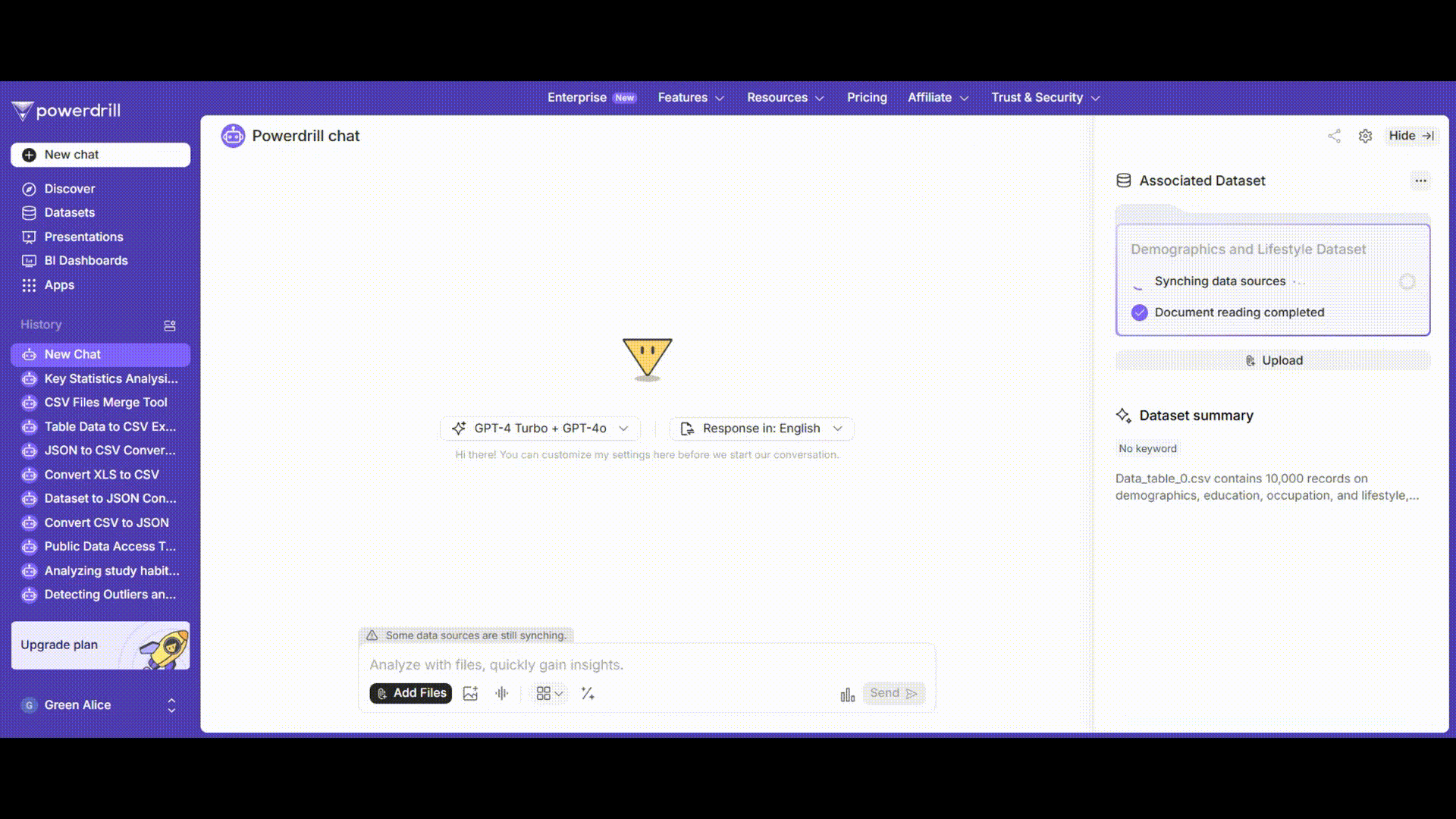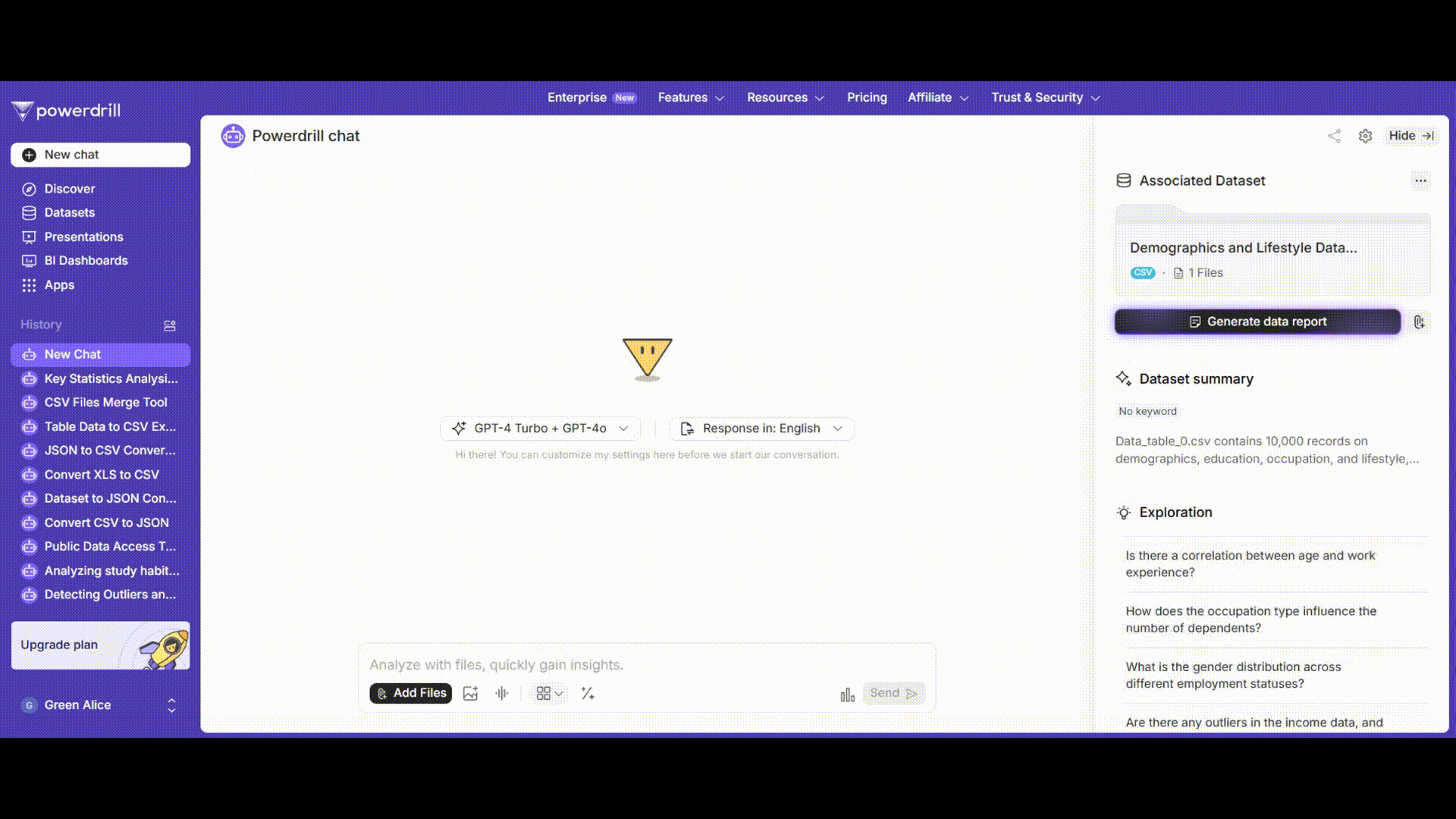
Go to powerdrill. The user-friendly interface allows you to easily upload your dataset. You can upload your data file (in common formats like CSV, Excel) from your computer or Dropbox cloud.
STEP 2: Selecting the Regression Task
After uploading the dataset, you need to communicate your analysis goals and research intentions to the AI according to your specific analysis requirements, enabling the AI to establish a regression analysis model. During this process, the AI functions like a personal research assistant, with whom you can have a conversation to discuss any information you want to know.
Simultaneously, the AI will also generate automated questions, which assist you in quickly discerning the internal relationships among the variables in the dataset.
Once the data is uploaded, Powerdrill AI can detect the variables. You should specify the dependent variable, which is "Annual Household Income" in our dataset. Subsequently, you are able to choose the independent variables you wish to incorporate into the regression model, such as "Age", "Education Level", "Occupation", "Work Experience", and so on.
Powerdrill AI is intelligent enough to handle various data types with minimal manual operation.
STEP 3: Model Training and Results
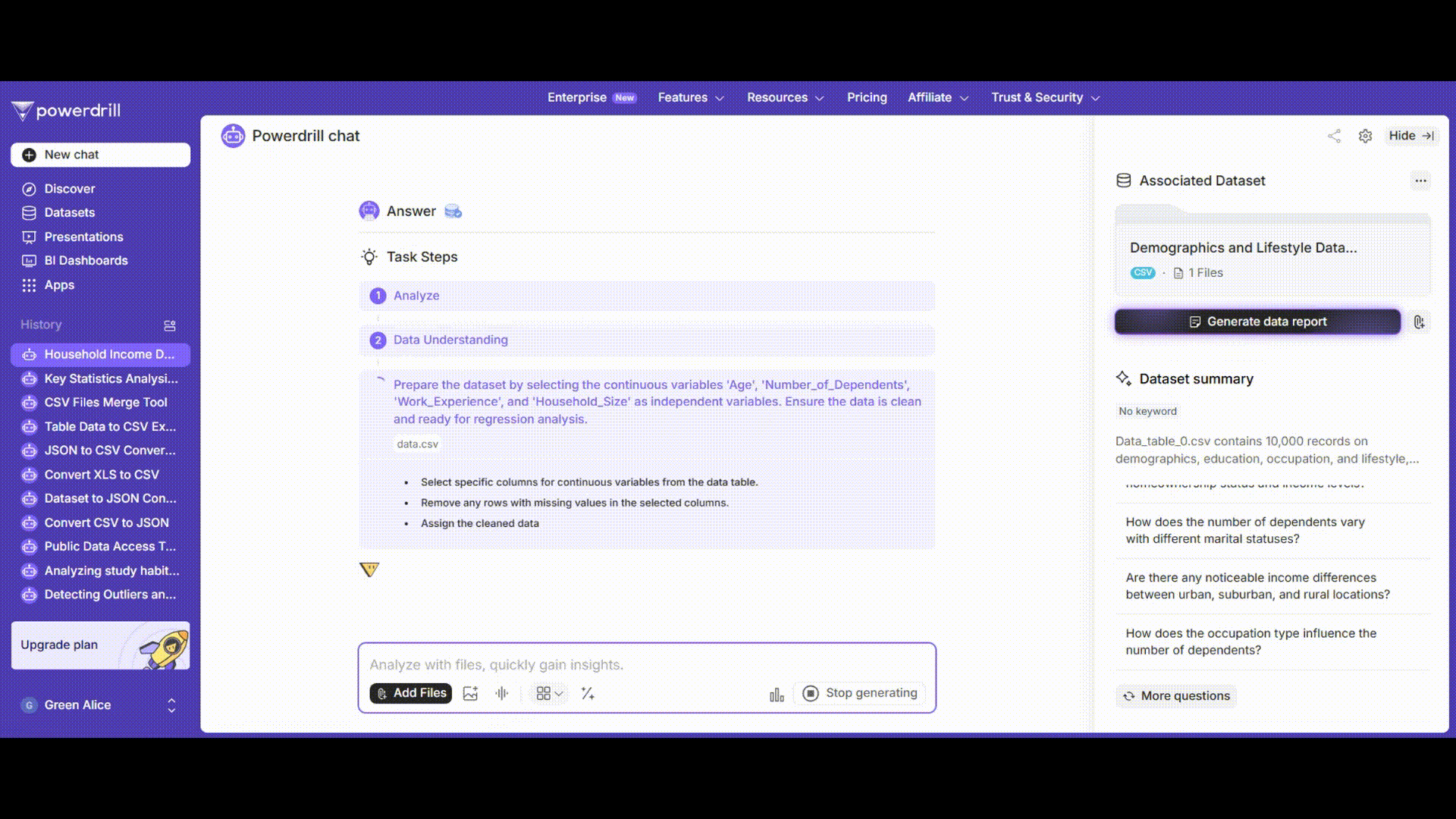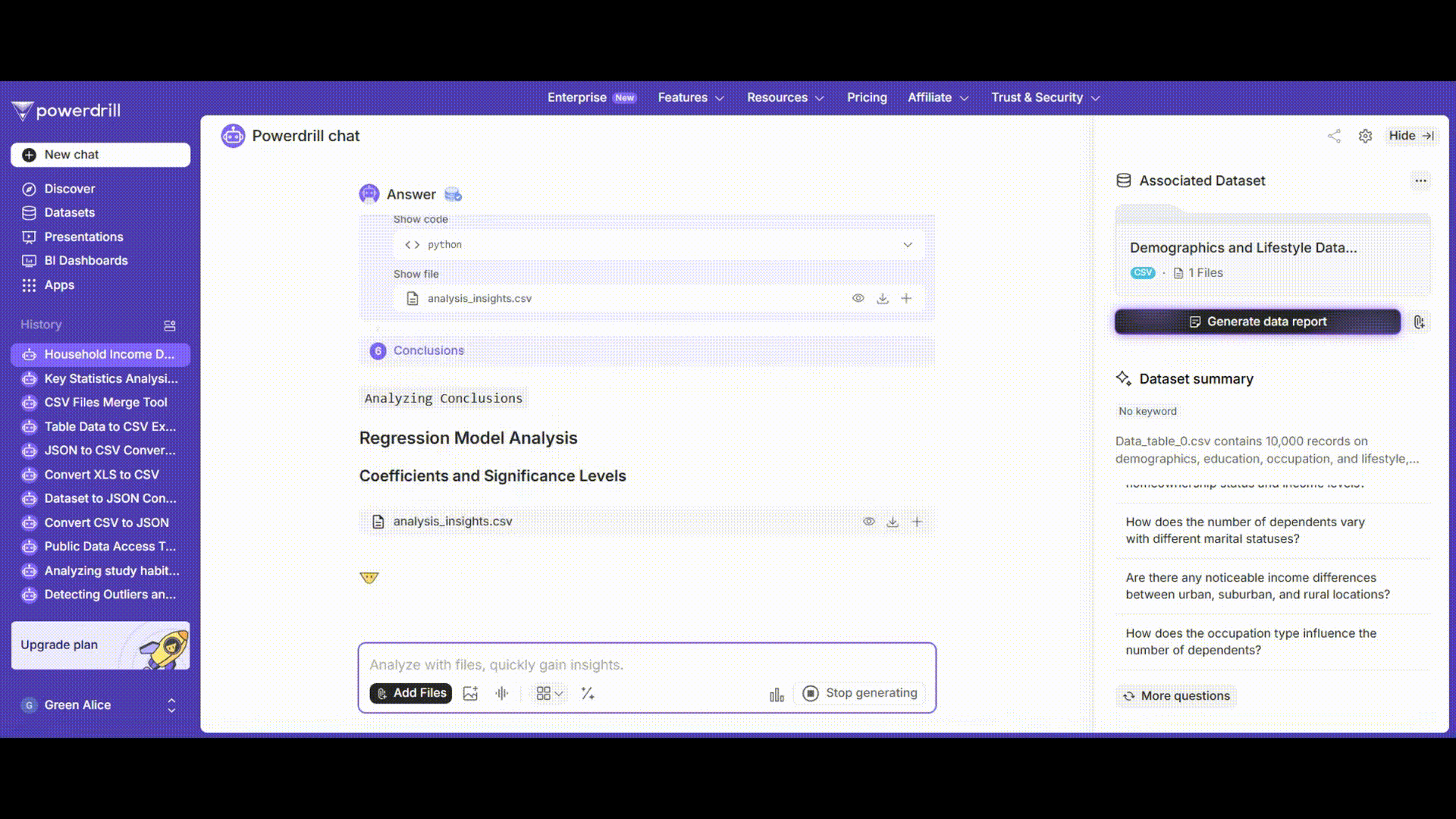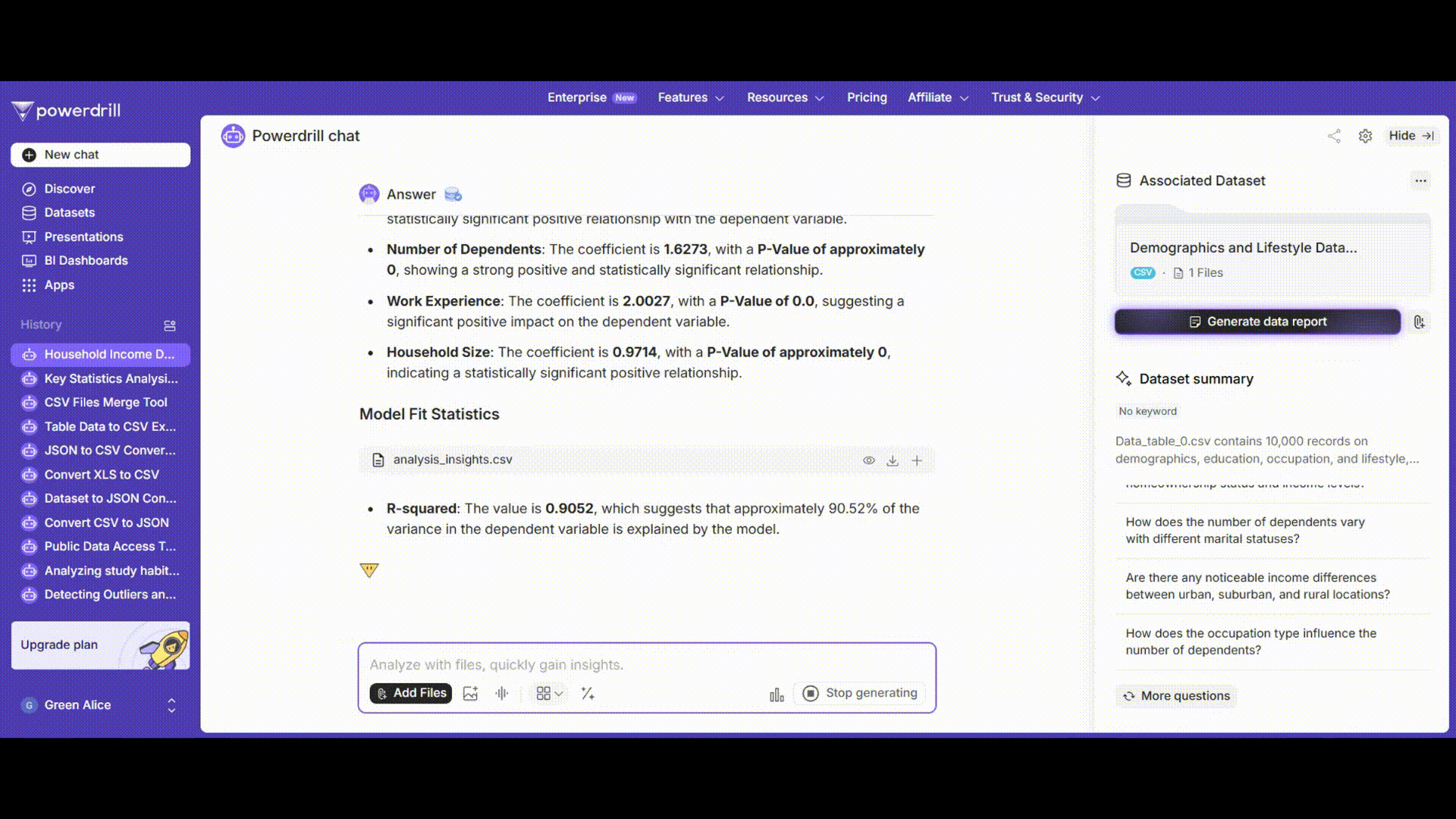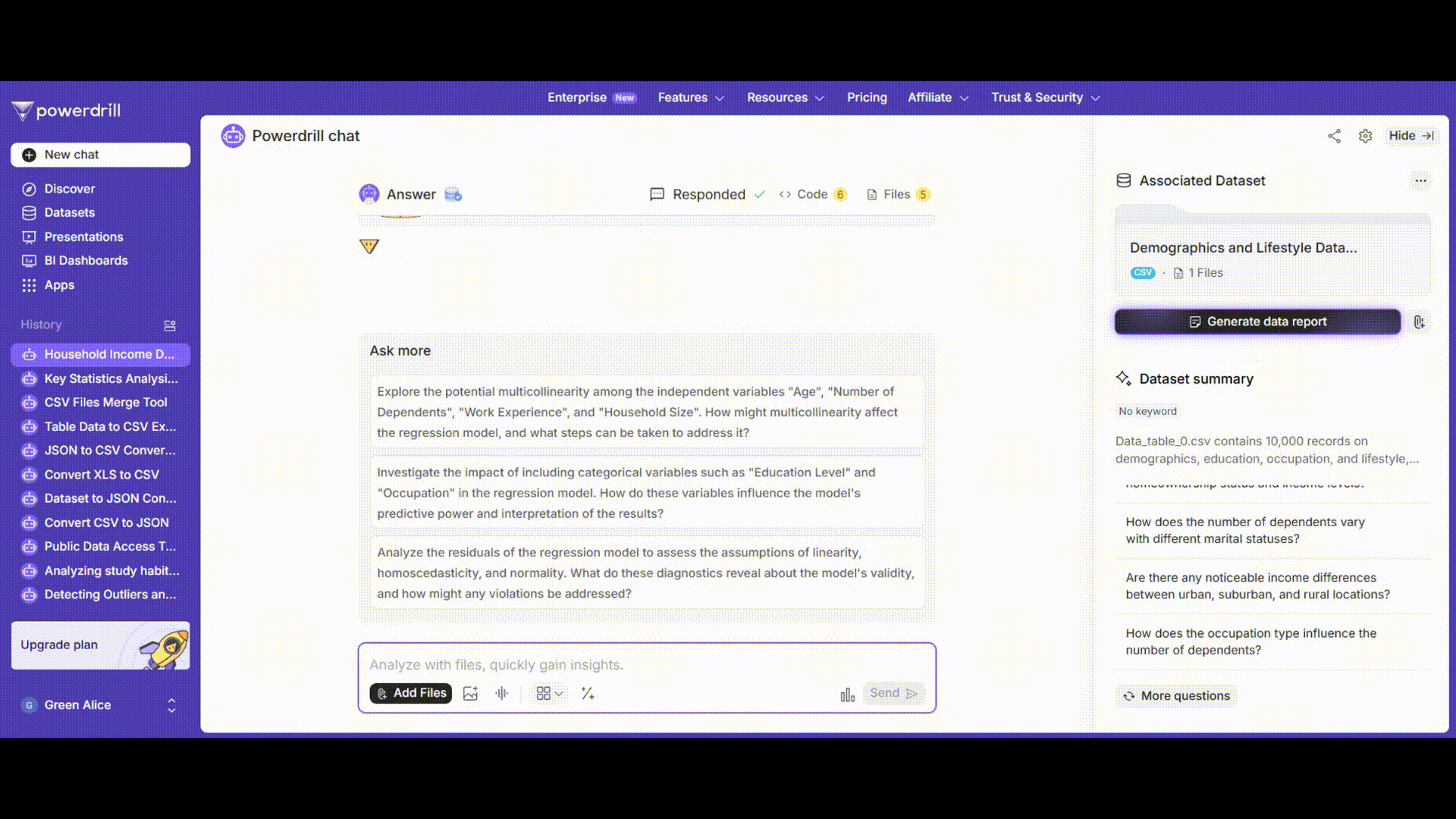
Powerdrill AI uses advanced machine - learning algorithms to perform the regression analysis. It will quickly train the model and provide you with detailed results.
The results will include not only the traditional regression coefficients and their significance levels but also visualizations. For example, it might show a scatter plot of the actual vs. predicted values of the annual household income, which helps you visually assess how well the model is performing. You can easily see if the predicted values are closely following the actual values.
Powerdrill AI can also handle complex data types more gracefully than traditional tools. It can analyze the relationships between variables in a more comprehensive manner. For instance, it can quickly identify if there are any non - linear relationships between "Work Experience" and "Annual Household Income" that might be overlooked in a simple Excel regression.
Empower Your Research with Powerdrill
Whether you are a beginner just starting to explore the world of data analysis or a more experienced researcher, regression analysis is a crucial tool. While Excel can be a good starting point for basic regression analysis, platforms like Powerdrill AI offer a more advanced, efficient, and user - friendly way to perform regression analysis, especially when dealing with complex datasets.
If you want to experience the ease and power of regression analysis with AI, head over to powerdrill.ai. Upload your data today and unlock the hidden insights in your data. Whether you are analyzing business data, scientific research data, or any other type of data, it can help you get accurate and meaningful results in no time.
Start today! Visit Powerdrill to upload your data!
Introduction to the Sample Dataset
The dataset used in this article focuses on understanding the factors influencing annual household income. You can download and practice data analysis through this page.
This synthetic dataset simulates various demographic and socioeconomic factors that influence annual household income. It can be used for exploratory data analysis, predictive modeling, and understanding the relationships between different features and income levels.
It encompasses a wide range of demographic and socioeconomic variables.
The "Age" of the primary household member captures the potential impact of work experience and life stage on income.
"Education Level" reveals how different educational attainments, from High School to Doctorate, can lead to varying income levels.
"Occupation" details various fields such as Healthcare, Education, Technology, and Finance, each having distinct earning potentials.
The "Number of Dependents" reflects how family structure affects disposable income.
"Location" (Urban, Suburban, Rural) accounts for regional differences in job markets and cost of living.
"Work Experience" in years, "Marital Status", "Employment Status", "Household Size", "Homeownership Status", "Type of Housing", "Gender", and "Primary Mode of Transportation" all contribute unique aspects to the complex relationship with annual household income.
This rich dataset allows for in-depth regression analysis to uncover the significant factors and their relative importance in determining household income.




